|
||||||
| 2024 年 10 月 1 日 改訂 | ||||||
pandas は、データ操作を行う Python のライブラリです。私は Excel file からデータを抽出するのに利用しています。 |
||||||
|
||||||
公式 HP に、様々なインストール方法がまとめられています。 pandas が入っているか確認
pip を用いる pandas を Python3 にインストールするには、以下のコマンドを入力してください。数分かかります。pip3 のアドレスについては、以下の「注意」を参照。
こちらを参照しました。 CentOS7 では、このままだと、pandas を含んだスクリプトを走らせた場合、以下のようなエラーが出ます。Ubunt24.04 では、上記で問題なく pandas がインストールされ、以下の操作は不要でした。
そこで、xlrd, openpyxl をインストールしてください。
xlrd は最新のバージョンでは動かないかもしれません。この場合は、以下の処理によってバージョンを下げました。
注意: 使う pip3 を間違えると、 xlrd などパッケージが正しくインストールされない場合があります。その場合は、実際に使っている python3 が保存されているディレクトリの pip3 を利用すると良いです。
yum を用いる
yum だと古いバージョンをインストールされる可能性があるようです。このため公式 HP では、pip を使ってインストールを勧めています。
ソースコードからインストール 以下を参照してください。私は pip を用いたインストールしかやったことがありません。
|
||||||
|
||||||
|
||||||
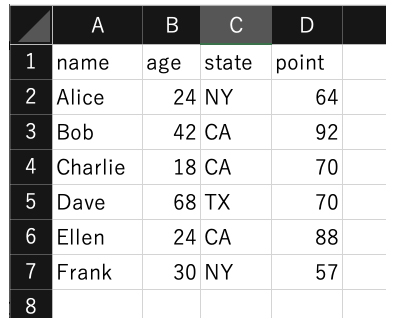
| アウトプット: | ||||||
 |
||||||
| ソースコード: | ||||||
#!/usr/bin/env python import pandas as pd df = pd.read_excel("sample_pandas_normal.xlsx")
|
||||||
|
||||||
 |
||||||
sort_eDNAres.tar.gz
|
||||||
|
||||||
 |
||||||
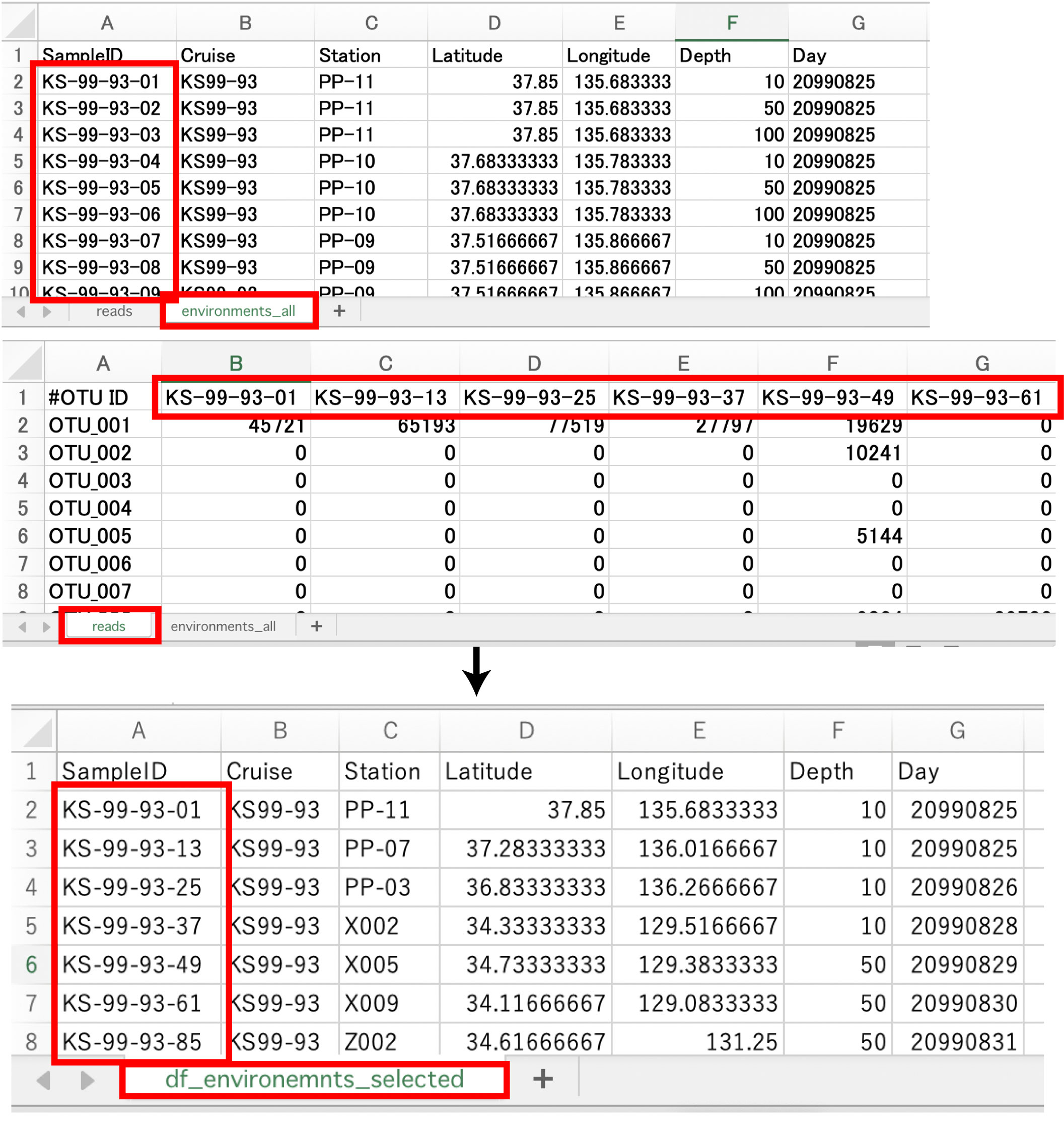
extractEnvironments.tar.gz
|
||||||
|
||||||
ライブラリ (xlrd, xlwt) を利用 こちらを参考にしました。
|
||||||
(2020 年 11 月)
|
||||||
|
||||||
| example_search_seibutsuGiken.tar.gz (2022/5/1) |
||||||
|
||||||
pandas で Excel ファイル (xlsx, xls) の読み込み
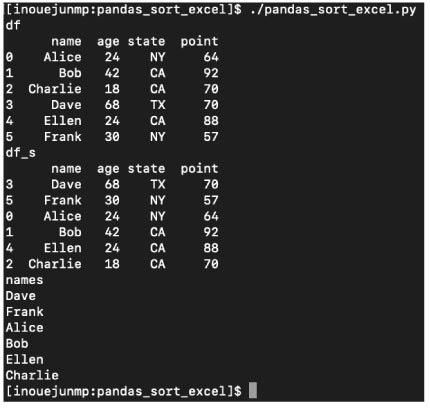
pandas.DataFrame, Series をソートする sort_values, sort_index
|
||||||
|
|